KI-unterstützte Entwicklung für Spektralwerk-Spektrometer
In vielen Unternehmen gelten Einschränkungen für die Nutzung von cloud-basierten KI-Dienstleistern wie Anthropic oder OpenAI, und das nicht ohne Grund. Die Kundinnen und Kunden verlangen Verschwiegenheitsvereinbarungen, und bei den sich häufig ändernden AGBs der KI-Dienstleister kann das heutige Versprechen, die eigenen Daten nicht zu verwenden, schon morgen nicht mehr viel gelten. Dazu steigt gerade beim Einsatz von autonomeren Agenten, die Vollzugriff auf die lokalen Daten haben, auch das Risiko, versehentlich sensible Daten preiszugeben.
Lokale KI-Setups mit frei nutzbaren LLMs wie Qwen, GLM oder MiniMax sind dafür mittlerweile praktikable Alternativen. Eine Einschränkung haben sie jedoch im Vergleich zu Claude und Codex: Der verfügbare Kontext ist kleiner. Der Kontext eines Sprachmodells ist in etwa dessen Arbeitsgedächtnis, es enthält sowohl die Aufgabenstellung als auch die relevanten Informationen wie den zu bearbeitenden Quellcode - und auch die nötige Dokumentation. Die Einschränkung der Kontextgröße ist dabei einmal schlicht durch den verfügbaren Arbeitsspeicher des Systems gegeben - gehostete Modelle im Rechenzentrum haben meist mehr RAM zur Verfügung als die Workstation unter dem Schreibtisch. Außerdem müssen die Modelle selbst für den Umgang mit großem Kontext trainiert worden sein.
Zum Zeitpunkt der Erstellung dieses Textes bieten Anthropics Claude und OpenAIs Codex ein Kontext von maximal 1 Million Tokens an (das sind rund 500.000 Wörter), während sich die freien Modelle gegenwärtig meist 256.000 Tokens (rund 130.000 Wörter) gleichzeitig merken. Das klingt auf den ersten Blick immer noch sehr groß. Wenn aber das LLM die ersten Korrekturschleifen über eine größere Codebasis gedreht hat, kann der Platz doch schneller eng werden als gedacht.
Erschwerend kommt hinzu, dass die lokalen Modelle kleiner sind, und ihr inhärentes Wissen zwangsläufig ebenfalls. Während also Claude vielleicht alle Kniffe im Umgang mit SCPI-Schnittstellen kennt, muss das lokale Modell ggf. etwas mehr an die Hand genommen werden.
MCP-Server: Flexibel lokale KI-Fähigkeiten erweitern
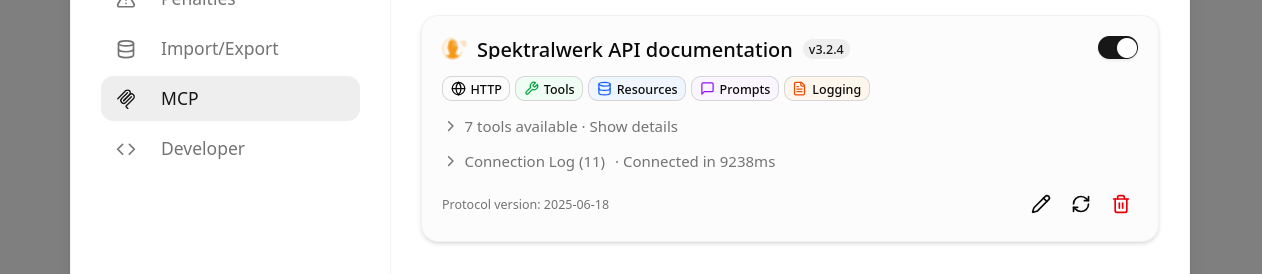
Aus diesem Grund bietet Silicann nun einen MCP-Server für die KI-basierte Arbeit mit der Spektralwerk-API an. MCP (Model Context Protocol) ist eine simple Schnittstelle, mit der LLMs die Nutzung von externem Wissen und der Zugriff auf externe Anwendungen ermöglicht wird. Der Spektralwerk-MCP-Server stellt nicht nur die gesamte API-Dokumentation für Spektralwerk zur Verfügung, sondern zusätzlich noch Hinweise zur Nutzung von SCPI, einigen Fachtermini sowie eine vollständige Liste von Fehlercodes, auf die das Modell stoßen könnte.
In unseren internen Tests waren dadurch auch lokale Modelle ohne besonders tiefe SCPI-Kenntnisse in der Lage, Anwendungen zu schreiben, die die Spektralwerk-API nutzen. Dabei wird dieses Wissen jeweils bedarfsgerecht und damit Token-sparend zur Verfügung gestellt: Wenn das Spektrometer einen spezifischen Fehlercode zurückliefert, dann muss das Modell auch nur diesen Code erfragen, statt ein Dokument mit sämtlichen möglichen Fehlern zu durchforsten. Auf diese Weise können sich die Modelle flexibel genau die Informationen besorgen, die sie für ihre aktuelle Aufgabe benötigen. Davon profitieren neben lokalen KIs natürlich auch Setups, die auf Claude oder Codex setzen.
Den Spektralwerk-API-MCP-Server einrichten
MCP-Server können über verschiedene Transportmechanismen zugänglich gemacht werden. Die Spektralwerk-Dokumentation wird über Streamable HTTP auf silicann.com zur Verfügung gestellt. Auf diese Weise müssen Nutzende in ihrer KI-Umgebung nur die Adresse https://silicann.com/sw15docs/mcp eingeben und haben sofort Zugriff.
Den MCP-Server mit llama.cpp nutzen
Eine beliebte lokale genutzte Umgebung mit einem Chat-Interface ist die Web-UI, die von Projekt llama.cpp direkt mitgeliefert wird.
Hier ist nur darauf zu achten, dass llama-server mit dem Parameter --webui-mcp-proxy gestartet wurde. Danach ist die Einrichtung denkbar einfach:
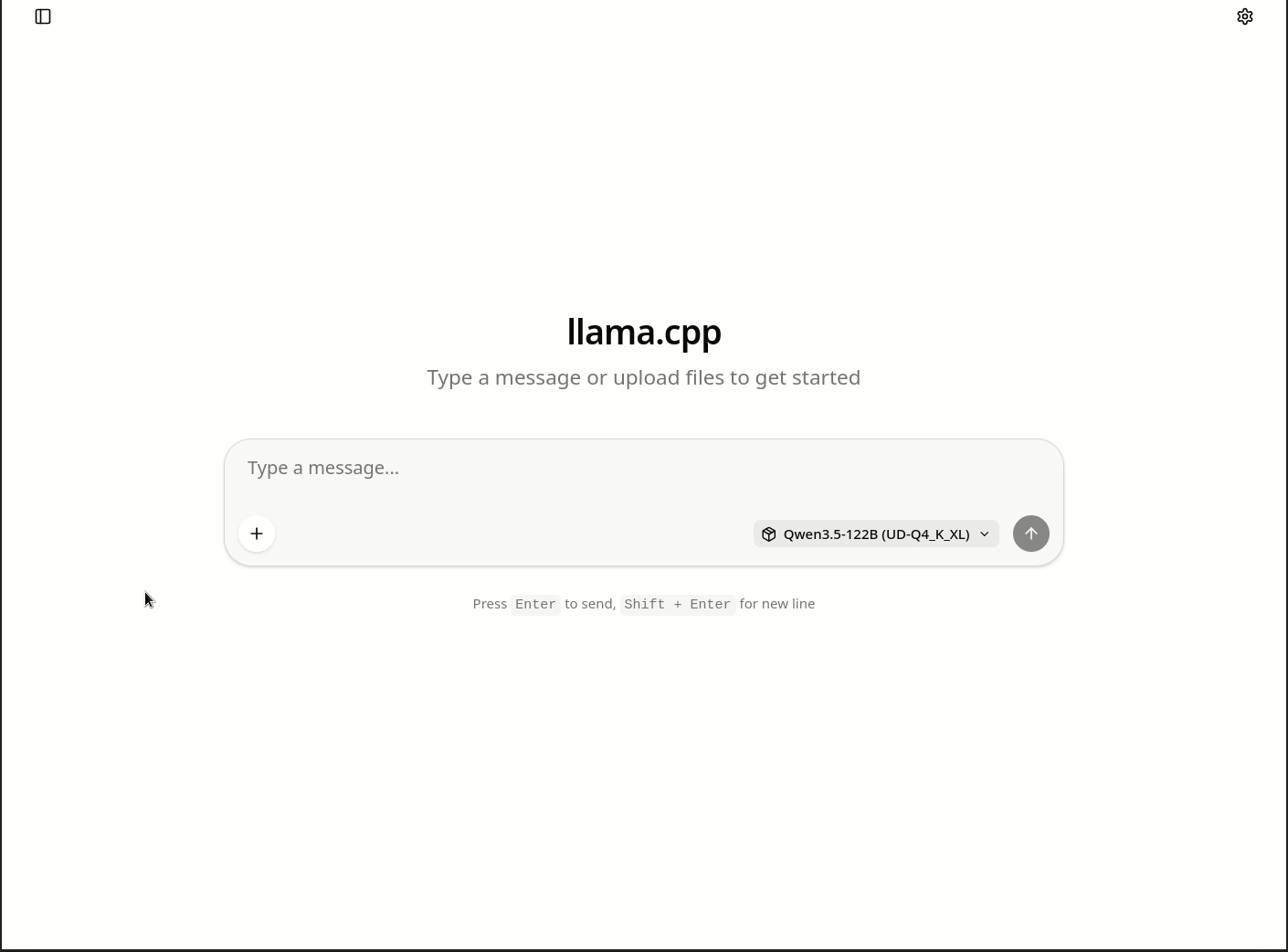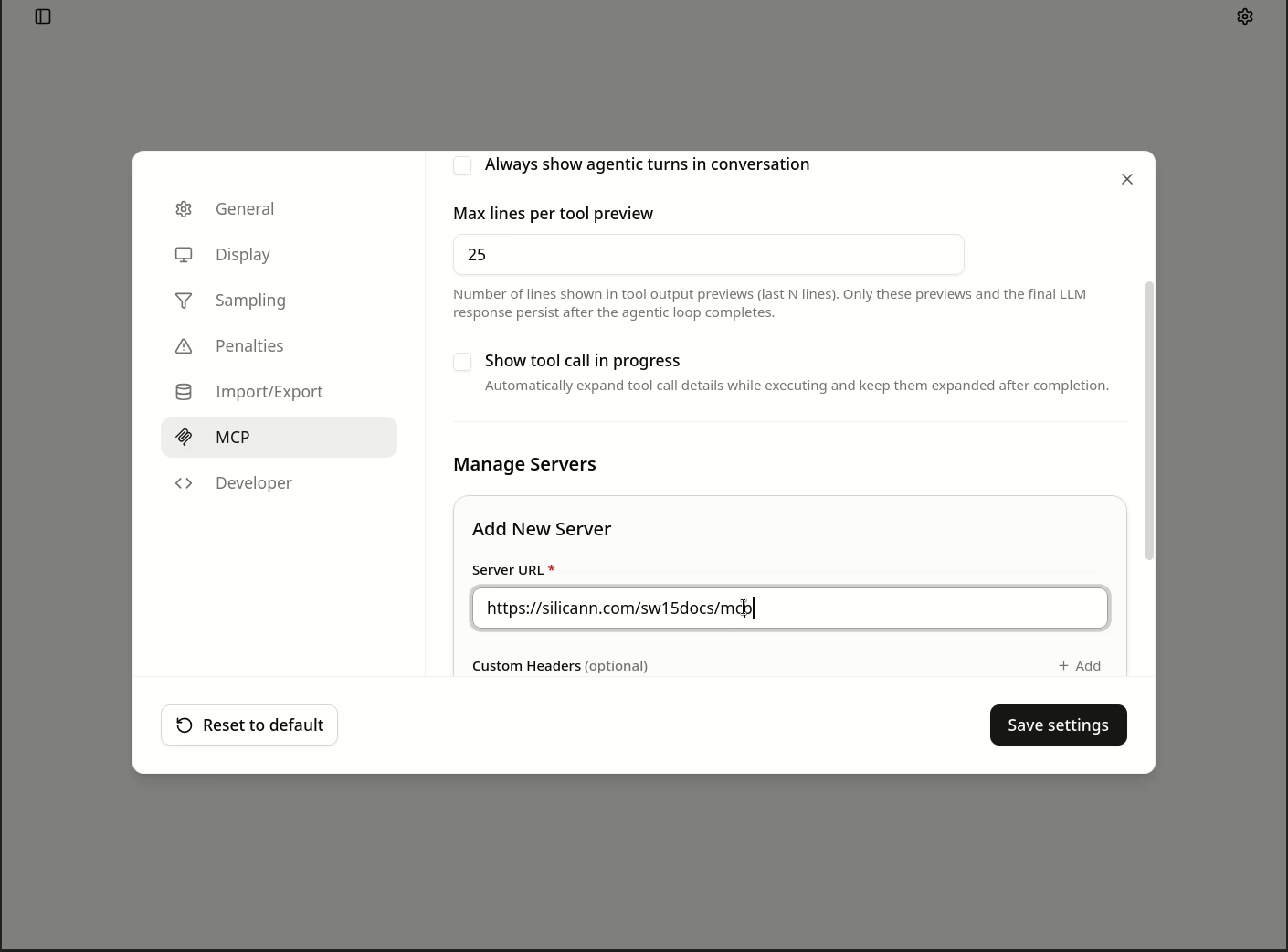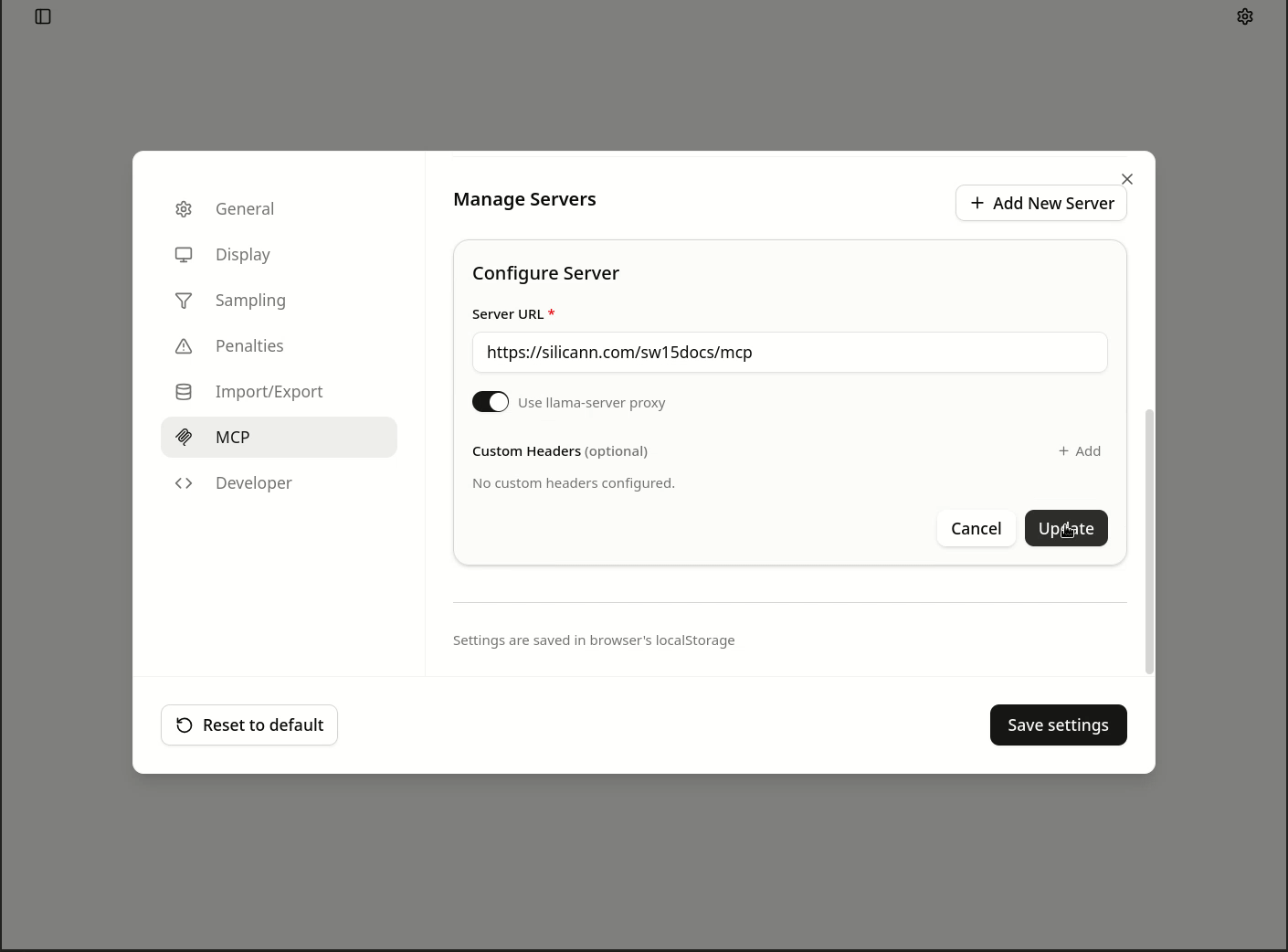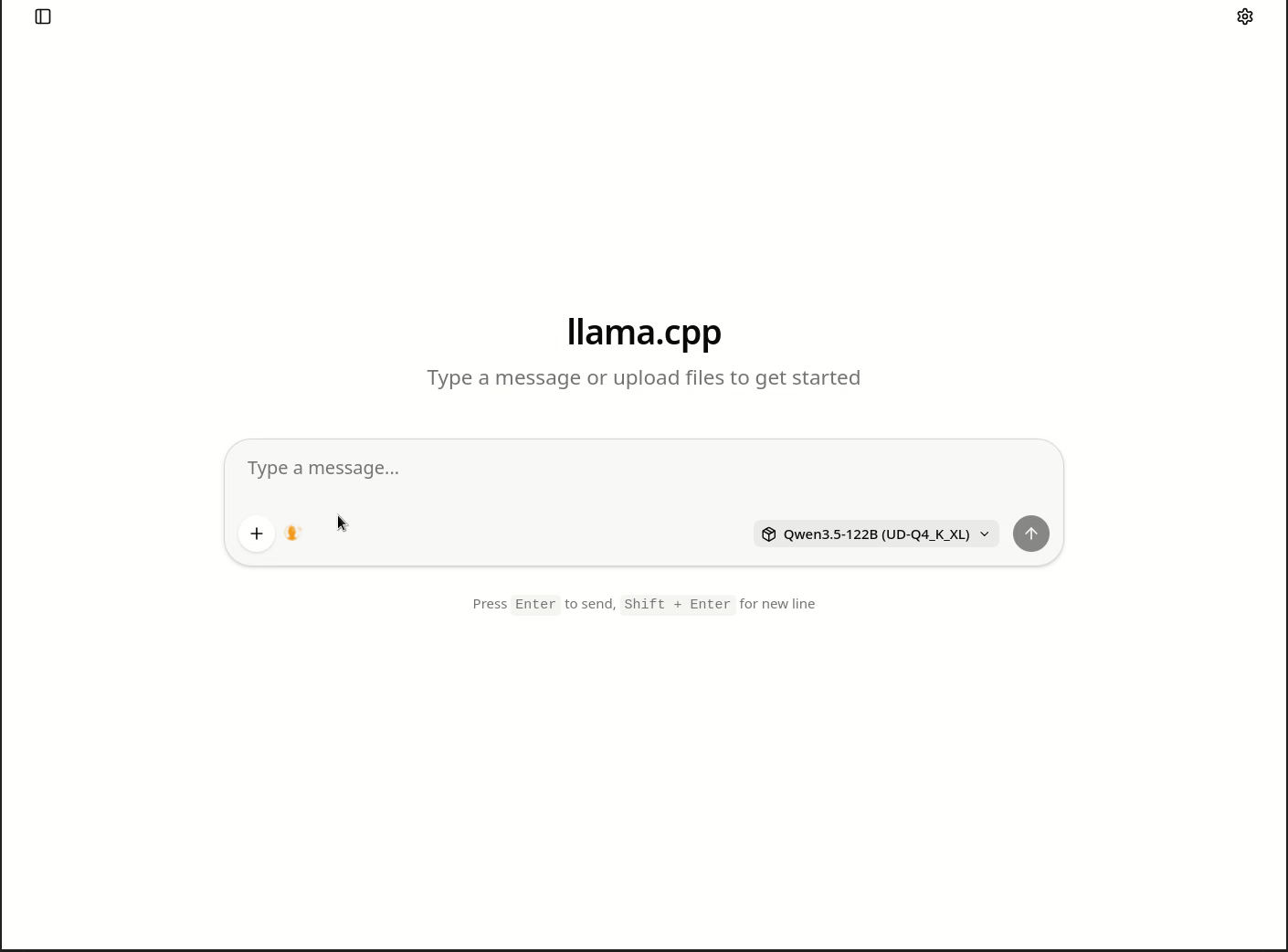
- Gehen Sie in den Einstellungen auf
MCP - Fügen Sie einen neuen Server hinzu und geben Sie dort die URL
https://silicann.com/sw15docs/mcpan - Speichern Sie den Eintrag, dann bearbeiten Sie mit Klick auf das Stiftsymbol den Eintrag noch einmal, aktivieren Sie die Option
Use llama-server proxy, und speichern Sie erneut.
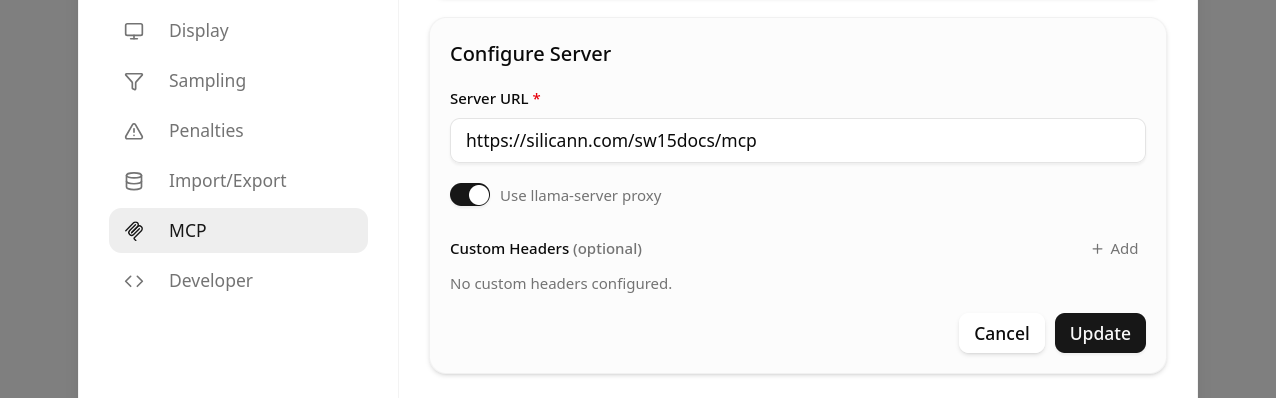
Das war es schon, nach erfolgreicher Einrichtung sollte llama.cpp auf den MCP-Server zugreifen und Titel, Icon und die verfügbaren Tools anzeigen, mit denen das KI-Modell auf die Spektrometer-Dokumentation zugreifen kann.
Ein Tipp noch, wenn Sie die Einstellungen schon geöffnet haben: Stellen Sie gleich die Agentic loop max turns auf einen höheren Wert, z.B. 30. Diese Option begrenzt, wie häufig das Modell während der Beantwortung einer Anfrage Tools nutzen darf, bevor es durch die Anwendung gestoppt wird. Da wir in diesem Fall im Sinne der Kontext-Sparsamkeit ja wollen, dass das LLM viele kleine Aufrufe tätigt, statt mit einem Mal die volle Dokumentation zu laden, sollte der Wert hier entsprechend erhöht werden.
Nach erfolgreicher Einrichtung ist das lokale LLM dann in der Lage, auf die Spektrometer-Dokumentation zuzugreifen und sie für die Lösung der Aufgabenstellung anzuwenden. Zu beachten ist hierbei, dass Sie für diese Anwendung auf Sprachmodelle zurückgreifen, die die Nutzung von Tools unterstützen. In den Beschreibungen der Modelle wird dann meist auf Tool Use, Tool Calling oder Agentic Use verwiesen.
Das folgende Beispiel zeigt, wie solch ein Modell dann auf die durch den MCP-Server zur Verfügung gestellten Tools zurückgreift, um die Aufgabenstellung zu lösen. Zunächst holt sich das Modell das Inhaltsverzeichnis der Spektrometer-Dokumentation und liest daraufhin Schritt für Schritt einzelne Kapitel, bis es alle nötigen Informationen zusammengesammelt hat. Am Ende kann es dann erfolgreich ein Script zurückliefern, dass wie gewünscht im Sekundentakt Spektren von einem Spektralwerk-Spektrometer zurückliefern kann.